
遅いインターネット回線とバッファブロートとFQ CoDel

皆様こんにちは。
弊社の事務所はインターネット接続にフレッツ光ネクストの回線を利用しています。
流行り病以降、近隣の方々もインターネットを激しく使うようになったらしく時間帯やサイトによってはとてもアクセスが重い時があります。
フレッツ網のIPv4(NTTの地域IP網内のPPPoE終端装置)が混みあっているのは界隈では良く知られた話で、IPv6のサイトであれば混雑した地域IP網ではなくNGN網を経由した通信となるため比較的快適にアクセスすることが出来ます。
DS-LiteやMAP-Eに対応しているISPであればv4/v6ともにNGN網経由の通信となるためこのような悩みとは無縁なのですが、弊社は固定IPv4アドレスのためにPPPoEを使わざるを得ない環境です。
(フレッツ光のIPoEで固定IPv4を利用できるISPもありますが)
バッファブロートとは
「ネットワークが混んでいる」とはどのような状況でしょうか。たとえば1Gbpsの回線を120人が10Mbpsずつ使いたい状況は混んでいるといえるでしょう。
理屈の上では端末側/サーバ側のTCP/IP実装がパケットロスを検知して一度に送信するデータを加減することで特定の通信フローが過度に帯域を占有することを避けることが出来るのですが、近年は通信経路上の機器が過度にパケットをキューイングする「バッファブロート」という現象が発生しています。
「キューサイズが大きいとパケットロスしないから良いのでは?」と思われがちですが、逆に考えるとボトルネック部分が輻輳している際も延々とキューイングされパケットロスしないためにTCP/IPが適切にフロー制御することが出来なくなります。
このような状態に陥ると、ブラウザの画面がずっとぐるぐるしたりWeb会議が安定しないような状態になります。
バッファブロートを計測する
「バッファブロート」を計測できるサイトがあります。
無負荷時のRTTと回線に負荷を掛けた際のRTTを計測して「バッファブロート」の影響を可視化してくれます。
https://www.waveform.com/tools/bufferbloat
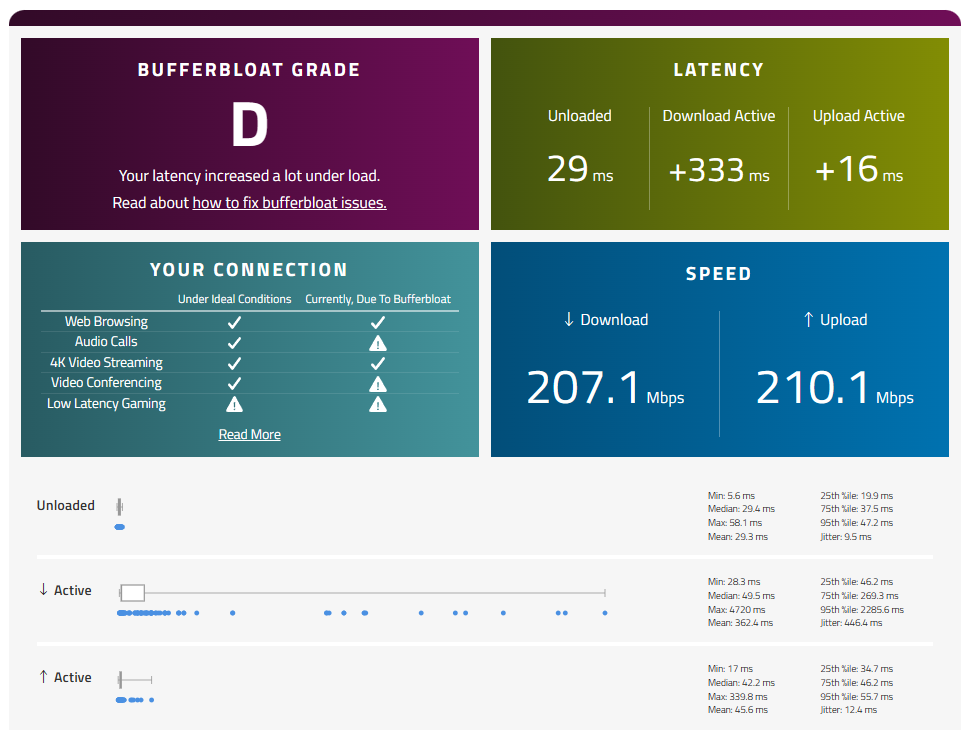
弊社の事務所のWindows-PCでIPv6を無効化してIPv4アクセス時のバッファブロートをテストしてみました。
無負荷時の95パーセンタイルは46.9msと「こんなものかな」という数字ですが、ダウンロード方向の95パーセンタイルは220.5msととんでもない数字になりました。一方、アップロード方向の負荷ではそこまでRTTはひどくなりません。
https://www.waveform.com/tools/bufferbloat?test-id=89ffca11-45d9-424a-95af-62693ceaee91
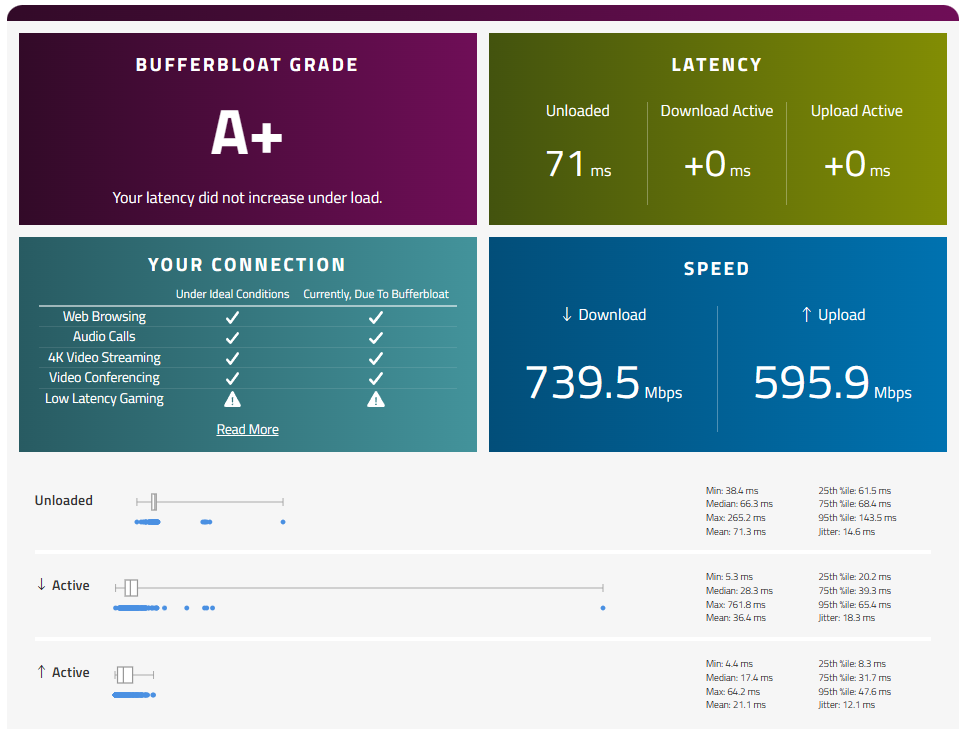
一方、IPv6を有効・IPv4を無効にして同じテストすると、バッファブロートが発生せずスピードも十分出ることが分かります。
https://www.waveform.com/tools/bufferbloat?test-id=1f436a79-f078-44de-956a-5bce2c401c16
やはり巷で言われるようにPPPoE終端装置が混雑しているようですが、混雑していることに付け加えるとダウンロード方向の「PPPoE終端装置→各契約者」のボトルネック箇所でバッファブロートが発生しているのだろうと推測できます。
ダウンロードの通信量がバッファブロートが発生しない程度の幅に収まるようにすれば、理屈の上ではバッファブロートは発生しないはずです。
バッファブロート対策にイケていると評判の「FQ CoDel」
バッファブロート対策にイケていると評判の「FQ CoDel(Flow Queue Controll Delay)」というQoSアルゴリズムがあります。
送信元と宛先のIPアドレス、プロトコル番号、送信元と宛先のL4ポート番号を元にフローを識別して動的にキューに振り分け、そのキューに対してCoDelアルゴリズムでQoS処理を行います。
FQ CoDelアルゴリズムはパラメータも少なくシンプルな仕組みです。
「RFC 8289 Controlled Delay Active Queue Management」で説明されているように、CoDelの特色はパケットがキューに入った(エンキュー)時刻とキューから出た(デキュー)時刻からキュー内滞留時間(sojourn time)を計算し、キュー内滞留時間を元にパケット破棄/出力を制御する点です。
パケットがキューに留まっている時間が”target”ミリ秒を越える状態が”interval”ミリ秒以上継続する場合は、キュー内滞留時間が”target”ミリ秒を下回るまでパケット破棄モードに入ります。
パケット破棄モードでどのくらいパケットを捨てるかは記事末尾の付録も参照してください。
WANルーターで「FQ CoDel」を設定する
弊社事務所のWANルーターはFreeBSD 14.2-RELEASEとPF、MPD5で構築しています。
FreeBSDのPFからFQ CoDelを利用するにはALTQを有効化したカスタムカーネルをコンパイルし直すか、dummynetカーネルモジュールをロードする必要があります。
流石に令和の世でカスタムカーネルを作るのは面倒なのでdummynetを使う方向で設定すると以下のような手順です。
pf.confでpassやblockをしている行より上にdummynetでキューイングするための行を追加
match on $wan_pppoe_if all dnqueue (2, 1)/etc/dnctl.confを新規作成
## WAN
# downlink
pipe 1 config bw 150Mbits/s
sched 1 config pipe 1 type fq_codel target 5ms interval 150ms quantum 1454 limit 10240 flows 10240
queue 1 config sched 1
# uplink
pipe 2 config bw 500Mbits/s
sched 2 config pipe 2 type fq_codel target 5ms interval 150ms quantum 1454 limit 10240 flows 10240
queue 2 config sched 2dummynetカーネルモジュールの読み込みとpfの再起動
kldload dummynet.ko
service dnctl onestart
service pf restartいろいろ大丈夫そうなら、OS起動時にdummynetモジュールをロードするようにしておく
sysrc dummynet_enable="YES"
sysrc dnctl_enable="YES"
sysrc dnctl_rules="/etc/dnctl.conf"FQ CoDel設定のポイント
上記の”/etc/dnctl.conf”が”FQ CoDel”を設定している箇所になります。
各パラメータを海外サイトとドキュメントの受け売りで解説します。
“target”および”interval”
キュー内滞留時間が”target”ミリ秒を越える状態が”interval”ミリ秒以上継続する場合は、キュー内滞留時間が”target”ミリ秒を下回るまでパケット破棄モードに入ります。
つまり、FQ CoDelのをチューニングするには”target”ではなく”interval”を調整します。
opnsenseの解説やdnctlのmanの記述「該当リンクで遭遇する最大RTT値と同じくらいにする」という内容と、事務所からの”ping archive.ubuntu.com”がだいたい150msであることから、ここではinterval 150msとしています。
1000msまで設定できますが「遅延がひどいパケットをさっさと捨てる」というFQ CoDelの趣旨を考えると、100ms~大きくても数百msくらいの幅で調整することになるでしょう。
“quantum”
パケットをデキューするときに一度に何バイト分を出力するか。デフォルトの1514バイトはちょうどEthernetの1フレーム分で、64バイトのショートフレームばかりの場合は23フレームを一度に送信することになります。
opnsenseのサイトの解説でもWANのリンクのInterfaceのMTUと同じにすべきとあることから、フレッツ光のPPPoE環境に合わせてquantum 1454としています。
“limit”
各フローごとのキュー長。CoDelではパケットのキュー内滞留時間で破棄するか否かを決定するのでキュー長を大きくしても意味はありません。
…のですが、opnsenseのサイトの解説によるとFreeBSDのFQ CoDelの実装の問題でlimitを縮めるとCPU時間の浪費やパケット遅延などの問題があるらしいとのことで、デフォルト値の10240のままとしています。
“flows”
識別したフローを振り分ける先のキューの数。
フロー数が設定値を越えた場合はどこかのキューに複数のフローが同時に割り当てられることになります。
フロー数を越えても端末の通信が切れるということにはなりませんが、イントラ内の端末台数と端末一台当たりどのくらいのTCP/UDPセッション数を使用するかを考えてパラメータを検討します。
端末一台あたり多い時で数百のTCPセッションを使用すると考えると、事務所などの規模で使うにはデフォルトの1024では足りないかもしれません。
ここではflows 10240としました。
“ecn”
ecn または noecnで、デフォルトはnoecnです。Windows10のデフォルト値もECNを利用してくれないのでnoecnのままとしました。
“bw”(帯域幅)
今回はダウンロード方向を「pipe 1 config bw 150Mbits/s」、アップリンク方向を「pipe 2 config bw 500Mbits/s」としました。
バッファブロートに効くと言われるFQ CoDelもTCPのフロー毎のRTTを観測しているわけではなく、あくまで設定個所の機器でのキューインク戦略を決めるものです。
つまり500Mbpsで入ってきたトラフィックを1Gbpsで出力するような設定にするとFQ CoDelによる制御が出来ません(ボトルネック未満の通信ではキューイングされないので)。
opnsenseのサイトによる解説では「ISPの契約帯域の85%くらいに設定してスピードテストをしてみる」ということでしたが、弊社事務所の環境で実験すると時間帯により100Mbpsから700Mbpsまでと変動するためあまり攻めた帯域幅を設定できません。
仮に帯域幅を595Mbpsとすることを考えると、一番バッファブロートがひどくなりそうな実効帯域100Mbpsの時間帯ではFQ CoDelの制御の前に網側でバッファブロートが始まると想定されます。
ここでは150Mbpsとし、理論的な最大帯域幅よりバッファブロートを抑制することによる体感速度の向上を取ることとしました。
終わりに
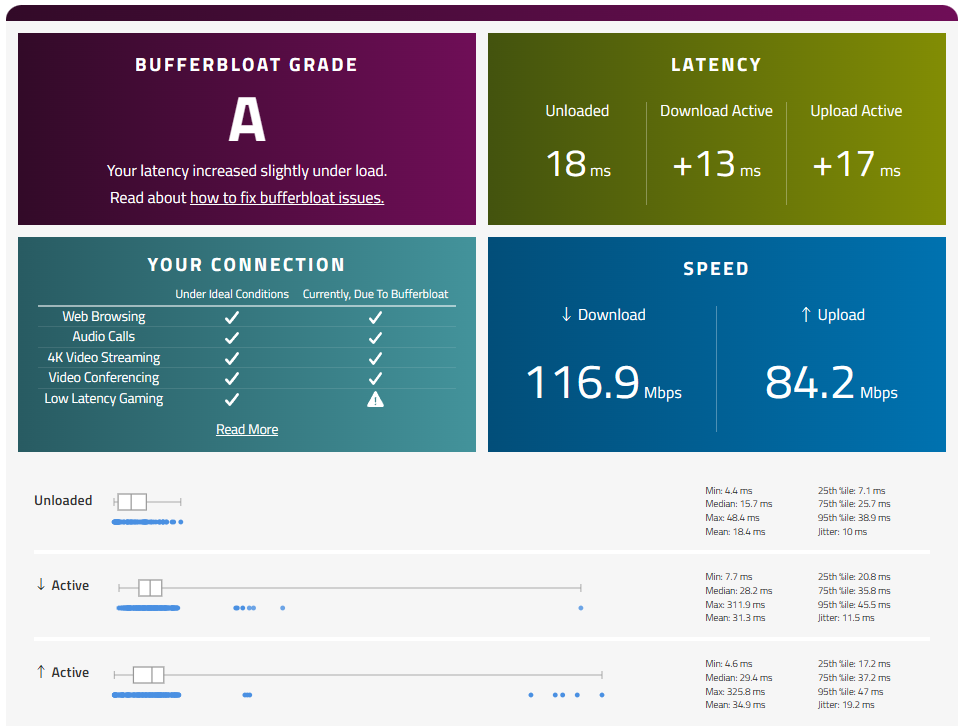
WANルーターへのFQ CoDel設定後にもう一度「バッファブロート」を計測すると、利用可能な帯域幅は狭くなりましたがダウンロード時(↓Active)のjitterも抑えられていることが分かります。
RTTが250msで帯域200Mbpsの回線よりはRTTが50ms未満で帯域100Mbpsの回線のほうがより仕事になるかと思います。
https://www.waveform.com/tools/bufferbloat?test-id=62945cb1-0203-48ab-8c44-c33ca88cdb1b
弊社事務所のイントラはIPv6に対応しているので速度だけを考えるとIPv6でインターネット接続してほしいのですが、IPv6アドレスがユニークローカルアドレスのためかULAより優先度の高いIPv4によるインターネットアクセスを端末のOSが選択することがあります。
Happy Eyeball対応なOS(Android, Windows10など)はIPv6で繋がってくれますが、そうでない場合やIPv6に対応していないサービスの場合はIPv4によるインターネットアクセスが必要な状況です。
DS-LiteやMAP-E対応の環境に移行したりフレッツ光クロスに移行するなど非PPPoEな環境にすれば良いと言われればそれまでなのですが・・・
FQ CoDelやバッファブロートというキーワードでこの記事にたどり着いた方の何かの参考になれば幸いです。
参考リンク
Bufferbloat and Internet Speed Test – Waveform
https://www.waveform.com/tools/bufferbloat
Fighting Bufferbloat with FQ_CoDel — OPNsense documentation
https://docs.opnsense.org/manual/how-tos/shaper_bufferbloat.html
FreeBSD System Manager’s Manual — IPFW(8)
https://man.freebsd.org/cgi/man.cgi?query=dnctl&sektion=8&format=html
Can’t make PF work with Dummynet on FreeBSD 14RC3 and RC4 | The FreeBSD Forums
https://forums.freebsd.org/threads/cant-make-pf-work-with-dummynet-on-freebsd-14rc3-and-rc4.90977/
RFC 8289 – Controlled Delay Active Queue Management
https://datatracker.ietf.org/doc/html/rfc8289
RFC 8290 – The Flow Queue CoDel Packet Scheduler and Active Queue Management Algorithm
https://datatracker.ietf.org/doc/html/rfc8290
IPv6のULAをIPv4より優先する | New technologies in our life
https://yoshi0808.github.io/new-technology/2021/06/26/ipv6-first/
Test your Happy Eyeballs.
http://he.test-ipv6.com/
インターネットの速度が遅い原因は多くの場合帯域幅とレイテンシーにあるとの指摘 – GIGAZINE
https://gigazine.net/news/20241010-internet-bandwidth/
付録 「RFC 8289」セクション5.5と5.6に挙げられている疑似コードにコメントをいれました
なんとなくCoDelがどのようにQueue内のパケット破棄を判定するかが分かると思います。
//5.5 Dequeue Routine デキュー時にどのようなロジックでパケット破棄を判定するのかのルーチン
packet_t* CoDelQueue::dequeue()
{
//"now"は現在時刻
//"r"はデキューした現在パケット
time_t now = clock();
dodequeue_result r = dodequeue(now);
uint32_t delta;
//dropping状態である場合
if (dropping_) {
if (! r.ok_to_drop) {
// キュー内滞留時間がTARGET未満であれば、dropping状態を離脱する
dropping_ = false;
}
//次のドロップまでの時間。
//現在のパケットをドロップし、次のパケットをデキューする。
//dequeueでドロップ状態から抜け出せなかったら、次のドロップをスケジュールする。
//「while」ループである理由は、大量の未処理パケットが原因でドロップ率が非常に
//高くなり、今すぐにでも次のパケットをドロップしたい状態になることがあるため。
//現在時刻が"drop_next_"※次回パケット破棄予定時刻(control_law関数の返り値)
//以降である かつ dropping状態である
while (now >= drop_next_ && dropping_) {
//現在パケットをdropし、このdropping状態で何回パケットを破棄したかを
//カウントする
drop(r.p);
++count_;
//次のパケットをデキューする
r = dodequeue(now);
//デキューしたパケットの"ok_to_drop"フラグがfalseであれば
//dropping状態を離脱する
if (! r.ok_to_drop) {
// leave drop state
dropping_ = false;
//デキューしたパケットの"ok_to_drop"フラグがtrueであれば
//次回パケット破棄予定時刻(drop_next_)を計算する
//破棄されたパケット(count_)が多いほどdrop_next_は短くなる
//デキューされたパケットに"ok_to_drop"フラグが立っている限り
//高頻度にパケットは破棄され続けるということ
} else {
// schedule the next drop.
drop_next_ = control_law(drop_next_, count_);
}
}
//処理がここに至るということはdropping状態ではない。
//現在パケットに"ok_to_drop"フラグが立っている状態はキュー内滞留時間がTARGETミリ秒より
//上の状態がINTERVALミリ秒の間続いたことを意味するため、現在パケットを破棄して
//dropping状態に移行する
} else if (r.ok_to_drop) {
//現在パケットを破棄
//次のパケットをデキューしてdropping状態に移行する
drop(r.p);
r = dodequeue(now);
dropping_ = true;
//最小値がTARGETを越えたが、最後にTARGET未満だった時の値に近い場合
//前回のサイクルでキューを制御したドロップ率が、現在それを制御するための良い
//出発点であると仮定する。
//最後のパケット破棄後、'drop_next'は最大でも'INTERVAL'ミリ秒である。
//よって、次回パケット破棄予定時刻として'now - drop_next'は良い近似である。
//現実の実装は若干異なっており、ここで挙げたLinuxの実装は広く普及している
//最新のdropping状態でdropされた回数 - 前回のdropping状態でdropされた回数
delta = count_ - lastcount_;
count_ = 1;
//deltaが1より大きい
//かつ「最後のパケット破棄時刻から現在時刻までの経過秒数」が「INTERVALミリ秒 ×16」より小さな場合
if ((delta > 1) && (now - drop_next_ < 16*INTERVAL))
//count_(最新のdropping状態でdropされた回数)を上記で計算していた'delta'とする
count_ = delta;
//control_law関数で次回パケット破棄予定時刻(drop_next_)を計算する
drop_next_ = control_law(now, count_);
//lastcount(前回のdropping状態でdropされた回数)変数に
//count_(最新のdropping状態でdropされた回数)を保存しておく
lastcount_ = count_;
}
//デキューされたパケットを関数の返り値とする
return (r.p);
}
//5.6. Helper Routines control_law(次回パケット破棄予定時刻の計算)やdodequeue(デキュー)
//次回パケット破棄予定時刻の計算
//引数に取った「時刻※」「パケット破棄回数」を元に、「次回パケット破棄予定時刻」として
//「時刻」+ (INTERVAL÷破棄回数の平方根)を返す
//たとえば、現在時刻として時刻を「0」、'INTERVAL'を100、破棄回数が16回とすると
//「0+(100ms/4)=25ms 」が次回パケット破棄時刻となる
//※引数は現在時刻だったり次回パケット破棄予定時刻だったりする
time_t codel_queue_t::control_law(time_t t, uint32_t count)
{
return t + INTERVAL / sqrt(count);
}
//実際のパケットのデキューを行い、キュー内滞留時間が'TARGET'以上か以下かを追跡するルーチン
//滞留時間が'TARGET'を超えている場合は、INTERVALミリ秒の間ずっと超えていたのかも確認する
typedef struct {
packet_t* p;
flag_t ok_to_drop;
} dodequeue_result;
dodequeue_result codel_queue_t::dodequeue(time_t now)
{
dodequeue_result r = { queue_t::dequeue(), false };
if (r.p == NULL) {
// queue is empty - we can't be above TARGET
//デキューしたパケットがNULLなら'first_above_time_'(最初にTARGETを越えた時刻)を0にしておく
first_above_time_ = 0;
return r;
}
//幅広い帯域幅に対応するため、CoDelは2つの異なるAQMアルゴリズムを実行する
//一つは、キュー内滞留時間を元に、MTUサイズのパケットを送信する時間が'TARGET'未満である場合。
//最初の"if"ブロックがその部分に該当する。
//そしてもう一つはデキュー待ちのパケット量に基づいており、MTUサイズのパケットを送信する時間が
//TARGET以上の場合に効果を発揮する。
//目的は、パケット間隔が過密にならないようキュー制御することで出力リンクの利用率を高く保つこと。
//(MTUサイズのパケットがボトルネック部分を通過するのにかかる時間だけパケット間隔を空けるようにする)
//2つめの"if"ブロックがその部分に該当する。
//キュー内滞留時間 = 現在時刻 - パケットがエンキューされた時刻
time_t sojourn_time = now - r.p->tstamp;
//キュー内滞留時間が'TARGET'未満 または キューサイズが'maxpacket_'以下
if (sojourn_time_ < TARGET || bytes() <= maxpacket_) {
// 少なくともキュー内滞留時間未満である
//'first_above_time_'(最初にTARGETを越えた時刻)を0にしておく
first_above_time_ = 0;
//キュー内滞留時間が'TARGET'以上 または キューサイズが'maxpacket_'以上
} else {
if (first_above_time_ == 0) {
// 滞留時間がTARGET未満からTARGET以上に遷移した
// 'first_above_time_'(最初にTARGETを越えた時刻)になってもまだ滞留時間が
//TARGET以上である場合はパケットの'ok_to_drop'フラグをtrueにする
first_above_time_ = now + INTERVAL;
} else if (now >= first_above_time_) {
r.ok_to_drop = true;
}
}
return r;
}